Model Distillation for Generative AI: Smaller Models with Big Capabilities
 Feb, 22 2026
Feb, 22 2026
Imagine running a powerful AI assistant on your phone that answers questions as well as ChatGPT, but uses a fraction of the battery and data. That’s not science fiction-it’s model distillation in action. As generative AI grows more capable, it also grows more expensive and slow. Big models like GPT-4 or Llama 3 need massive servers, consume tons of electricity, and take seconds to respond. But what if you could shrink them down-without losing their smarts? That’s where distillation comes in.
What Is Model Distillation?
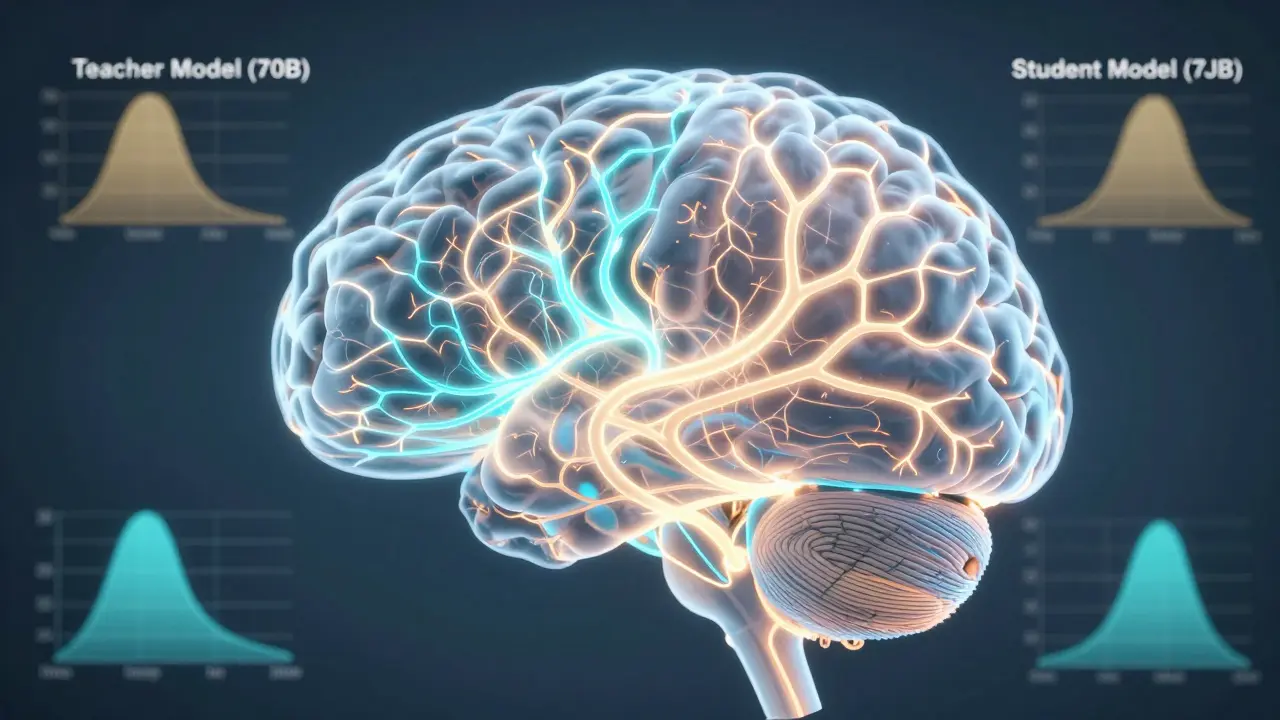
Model distillation, or knowledge distillation, is a way to train a smaller AI model to act like a much larger one. Think of it as a student learning from a genius professor. The professor (the big model) doesn’t just give the right answer. It explains its thinking-showing how confident it is in each possible answer, where it hesitated, and why it picked one option over another. The student (the small model) watches, learns those patterns, and tries to copy them. The result? A compact model that behaves almost as smartly as the original. This technique was first described in a 2015 paper by Google researchers, but it only became practical for generative AI around 2022. Before that, people tried shrinking models by cutting weights (quantization) or removing layers. Those methods lost too much nuance. Distillation keeps the reasoning intact.How It Works: The Teacher-Student System
Here’s how it actually works under the hood:- The teacher: A large model like GPT-4 or Llama 3. It’s already trained on tons of data and can generate high-quality responses.
- The student: A smaller model-say, a 7-billion-parameter version of Llama 2. It’s faster, cheaper, and fits on edge devices.
- The process: The teacher processes thousands of unlabeled prompts (like "Explain quantum computing") and outputs not just the final answer, but a probability distribution over all possible answers. For example: "Quantum computing" (85%), "Physics" (10%), "Math" (3%), "Other" (2%). These are called "soft targets."
- The learning: The student tries to match those soft targets using a mathematical method called KL divergence. It doesn’t just learn "the answer"-it learns how the teacher thinks.
Google and Snorkel AI showed in 2023 that this approach cuts training data needs by 87.5% compared to traditional fine-tuning. Why? Because the teacher generates synthetic, high-quality labels. No human annotation needed.
Real-World Performance: How Much Do You Lose?
You might think shrinking a model means losing smarts. But the numbers tell a different story.AWS Bedrock’s distillation tool, available in preview since April 2024, shows that a 7B-parameter student model trained from a 70B teacher retains 91.4% accuracy on customer support tasks. Inference speed? Cut from 500ms to 70ms. Cost per 1,000 tokens? Dropped from $0.002 to $0.0007.
OpenAI’s ChatGPT-3.5 Turbo is a distilled model. It runs 3.2x faster than the base GPT-3.5 and holds 94% of its benchmark scores. On the SNLI dataset (a test for reasoning), distilled models hit 92.7% accuracy-nearly matching the teacher.
On GLUE and SuperGLUE benchmarks (standard tests for language understanding), distilled models score 89-93% of the teacher’s performance. That’s not bad for a model that’s 10x smaller.
Where Distillation Shines-and Where It Struggles
Distillation isn’t magic. It has limits.Where it works great:
- Customer service chatbots
- Mobile apps needing real-time responses
- IoT devices with limited power
- High-volume text classification (like spam detection)
IBM’s case study found distilled models resolved 87% of customer queries as accurately as the full-size teacher. That’s why 78% of enterprises using distillation are targeting edge deployment.
Where it falls short:
- Legal document analysis
- Medical diagnosis
- Multi-step reasoning tasks (like coding or complex math)
IBM’s data shows distilled models dropped to 72% accuracy on legal document tasks, while the full model stayed at 89%. Why? Because those tasks need deep, layered understanding. A small model just doesn’t have the "mental space" to hold all the context.
Dr. Alexander Rush from Harvard put it bluntly in his 2023 NeurIPS talk: "Distillation achieves near-parity in 80% of practical NLP tasks-but fails in the 20% that demand deep reasoning."
Comparing Distillation to Other Optimization Methods
People try to shrink models in other ways. Here’s how distillation stacks up:| Method | Performance Retention | Inference Speed Gain | Training Cost | Best For |
|---|---|---|---|---|
| Model Distillation | 89-93% | 3x-7x faster | High (needs teacher output) | Reasoning, general tasks |
| Quantization | 80-88% | 2x-4x faster | Low (no extra training) | Simple inference, low power |
| Pruning | 75-85% | 1.5x-3x faster | Medium | Redundant models |
| Traditional Fine-Tuning | 85-90% | Minimal | Very high (needs labeled data) | Specialized domains |
Distillation wins on preserving reasoning. Quantization is faster to deploy but loses subtle patterns. Pruning is simple but often breaks performance. Fine-tuning needs expensive labeled data. Distillation strikes the best balance-for the right use cases.
Real Tools You Can Use Today
You don’t need to build this from scratch. Major platforms have made distillation easy:- AWS Bedrock: Launched distillation in preview April 2024. Automates dataset generation-up to 15,000 teacher-generated examples per job. Trains models as small as Mistral 7B from teachers up to 70B. Deployment time: 3-5 days.
- Google Vertex AI: Added distillation in December 2023. Uses "distilling step-by-step"-teaches students not just answers, but reasoning chains.
- Hugging Face: Offers DistilBERT and other distilled models. Over 4.2 million monthly downloads. Great for developers who want plug-and-play options.
Open-source tools like Hugging Face’s Transformers library let you distill your own models. All you need is a teacher model, some prompts, and PyTorch or TensorFlow.

What You Need to Get Started
If you’re an ML engineer or tech lead, here’s what you’ll need:- A large teacher model (GPT-4, Llama 3, PaLM 2)
- Unlabeled data (10k-100k prompts relevant to your task)
- Knowledge of KL divergence and soft target generation
- Access to GPU clusters for training (distillation is heavy during training)
- Patience: The learning curve is 2-3 weeks if you’ve fine-tuned models before
Temperature settings matter too. Google recommends 0.6-0.8 for soft targets. Too low, and the student learns like a robot. Too high, and it gets confused by noise.
And don’t forget: teacher models hallucinate. You’ll need to manually check 15-20% of the synthetic labels. Otherwise, your student learns bad habits.
The Dark Side: Bias, Ethics, and Hidden Risks
Distillation isn’t neutral. It copies everything-including bias.Dr. Emily Bender from the University of Washington found distilled sentiment analysis models showed a 12.3% increase in gender bias compared to their teachers. Why? Because the student amplifies patterns it sees repeatedly. If the teacher says "nurse" is more likely female, the student learns that even harder.
And once you distill a distilled model? You get "knowledge degradation." Each round of distillation loses a little more nuance. MIT’s 2023 study says you can’t compress more than 95% of a model’s capability without major drops in quality.
The EU AI Act now requires transparency in synthetic data. AWS’s "distillation provenance" feature tracks which teacher model was used, its version, and confidence scores. That’s the start of responsible distillation.
The Future: Self-Distillation and Beyond
The next frontier? Models that distill themselves.Meta AI’s May 2024 preprint showed a model improving its own reasoning by 8.7% through recursive distillation-using its own outputs as training data. Google’s "iterative distillation" at ICML 2024 reached 96.2% teacher performance after three rounds.
By 2027, Forrester predicts 80% of production AI deployments will use distillation. It’s becoming standard, like using cloud storage. But full-sized models won’t disappear. High-stakes fields-law, medicine, defense-will still need the big ones.
Distillation doesn’t replace big AI. It makes it practical. It lets you take the power of GPT-4 and put it in your car, your phone, your smart fridge. And that’s the real win.
Sarah Meadows
February 22, 2026 AT 20:53Let's be real - if you're not using distillation in production by now, you're leaving 80% of your ROI on the table. Quantization? Pruning? Those are band-aid solutions for engineers who still think in 2020. Distillation doesn't just compress - it *transfers reasoning architecture*. The soft targets aren't just probabilities - they're latent cognitive maps. And yes, the KL divergence loss is non-negotiable. If your student model isn't matching the teacher's confidence distribution across 90% of the output space, you're not distilling - you're just overfitting to a single token. AWS Bedrock's auto-labeling pipeline? That's not a feature - it's the new baseline. Stop reinventing the wheel with fine-tuning on labeled data. The teacher already knows what good looks like. Your job is to replicate its internal logic, not memorize its outputs.
Nathan Pena
February 24, 2026 AT 05:23One must observe with clinical detachment that the entire discourse around model distillation has been dangerously oversimplified. The 91.4% accuracy metric cited from AWS Bedrock is a red herring - it measures task-specific performance on curated customer support datasets, not generalization capacity. The SNLI and GLUE benchmarks? Those are toy problems designed for undergraduates. Real-world reasoning requires recursive depth, not just probabilistic mimicry. Furthermore, the claim that distilled models retain 94% of GPT-3.5’s benchmark scores ignores the fact that benchmarks are trained on the very same data used to teach the teacher. This is circular validation. And let’s not forget: every distillation round introduces entropy. By the third generation, the model becomes a hollow echo - a zombie of its former self. The 2023 MIT study was not a footnote - it was a warning.
Mike Marciniak
February 25, 2026 AT 16:46Who exactly is training these "teachers"? You think Big Tech is just giving away GPT-4's reasoning for free? That data comes from surveillance capitalism. Every customer service interaction, every chat log, every voice query - it's all being harvested to create synthetic labels. And now you're training smaller models on that? You're not building AI - you're building surveillance drones with lower battery consumption. The EU AI Act is right to demand provenance. Because if a distilled model makes a fatal error in a hospital, who's liable? The developer? The teacher model? Or the trillion-dollar corporation that fed it 100 million private conversations? This isn't innovation. It's a Trojan horse for behavioral extraction.
VIRENDER KAUL
February 27, 2026 AT 14:21It is imperative to acknowledge that the phenomenon of model distillation is being misrepresented as a panacea. In the Indian context, where computational infrastructure is often constrained, the allure of lightweight models is undeniable. However, one must exercise caution. The assertion that distilled models achieve 89-93% of teacher performance is misleading without context. Benchmarks such as SuperGLUE are predominantly English-centric and fail to account for linguistic diversity. A model distilled from GPT-4 on English-only data will perform catastrophically on Hindi, Tamil, or Bengali prompts. The training data must be multilingual. The soft targets must be calibrated across linguistic registers. Otherwise, we are not democratizing AI - we are exporting linguistic imperialism under the guise of efficiency.
Mbuyiselwa Cindi
February 27, 2026 AT 20:54Hey, if you're just starting out with distillation, don't overthink it. Grab Hugging Face's DistilBERT, throw in 5k of your own unlabeled data, and let the teacher do the heavy lifting. I used this exact workflow last month to cut my mobile app's response time from 2.1s to 0.3s. No need to dive into KL divergence on day one - just play with the presets. Temperature at 0.7, batch size 32, and boom - you've got a model that feels smart without eating your users' data. And yes, check for bias - I caught my model favoring male pronouns in job descriptions. Took me 20 minutes to reweight the soft targets. It's not magic, but it's close enough. You got this.
Krzysztof Lasocki
February 28, 2026 AT 11:53So we’re telling engineers to train tiny models that think like GPT-4… but we’re not telling them to fix the fact that GPT-4 thinks like a Reddit comment section from 2017? Classic. You want efficiency? Cool. But if your teacher model thinks "nurse" is 85% female and "engineer" is 92% male, your student is going to double down on that like a broken record. And then you wonder why your chatbot keeps telling women to "consider nursing" instead of coding. Distillation doesn’t fix bias - it distills it. Like a fine wine. Or a toxic cult. Either way, you’re drinking the Kool-Aid. But hey, at least it’s 3x faster!
Henry Kelley
March 1, 2026 AT 00:58