Task-Specific Fine-Tuning vs Instruction Tuning: Which LLM Strategy Wins for Your Use Case?
 Jan, 18 2026
Jan, 18 2026
Want your LLM to handle customer service chats or analyze medical records? You can’t just plug in a base model and expect it to work. You need to fine-tune it. But here’s the catch: there are two main ways to do it, and picking the wrong one could cost you time, money, and accuracy. Task-specific fine-tuning and instruction tuning aren’t just technical jargon-they’re strategic choices that determine whether your AI feels like a helpful assistant or a narrow, brittle tool.
What’s the Difference Between Task-Specific Fine-Tuning and Instruction Tuning?
Think of a base LLM like a recent college grad with a broad education but no job experience. Models like Meta’s Llama 3 or Google’s FLAN-T5 have been trained on massive amounts of text-they can write essays, answer trivia, and summarize articles. But they don’t know how to follow your exact instructions. That’s where fine-tuning comes in. Task-specific fine-tuning is like training that grad for one job: medical coding. You give it 500-1,000 labeled examples-say, patient notes paired with correct ICD-10 codes-and tweak the model so it gets really good at that one thing. It becomes a specialist. On the flip side, instruction tuning is like training the same grad to handle any job request: “Summarize this report,” “Translate this email,” “Classify this document,” “Write a follow-up message.” You feed it thousands of diverse instruction-response pairs across dozens of tasks. The goal isn’t mastery of one thing-it’s adaptability. The difference isn’t just in data-it’s in outcome. A task-specific model might hit 98.7% accuracy on ICD-10 coding (like Mistral Healthcare’s model), but if you ask it to summarize a patient’s history, it might fail completely. An instruction-tuned model might only hit 95% on that same coding task, but it’ll still handle summaries, translations, and follow-ups without breaking a sweat.When to Use Task-Specific Fine-Tuning
Use task-specific fine-tuning when you need maximum performance on a single, well-defined task. This isn’t about versatility-it’s about precision. For example, JPMorgan Chase used task-specific fine-tuning on a custom model to classify SEC filings with 94.1% accuracy. That’s critical in finance, where a single misclassification can trigger compliance issues. Similarly, in healthcare, specialized models for ICD-10 coding or radiology report generation rely on this approach. The data is structured, the output is binary or categorical, and there’s little room for error. But here’s the trade-off: you pay for that precision with fragility. Research from Youssef Hussein (November 2024) shows task-specific fine-tuning can cause up to 38% degradation in unrelated capabilities. That’s called catastrophic forgetting. Your model forgets how to write emails, answer general questions, or even hold a conversation. If you later want to add another task-say, drafting internal memos-you’ll need to retrain the whole model, or risk breaking what you already fixed. Training time is also shorter: 12-48 hours on an 8x NVIDIA A100 setup. But implementation? It takes 2-3 weeks. Why? Because you need clean, high-quality labeled data. If your training set is messy or biased, your model will be too. And if you’re in a regulated industry like finance or healthcare, you’ll need to document every example. That’s not just technical work-it’s legal work.When to Use Instruction Tuning
Instruction tuning is the go-to for any application where users will ask unpredictable things. Think chatbots, virtual assistants, internal knowledge bases, or customer support tools. The key advantage? Generalization. Instruction-tuned models like Llama3-70B-Instruct (released January 2026) can handle 100+ tasks without retraining. They’re trained on datasets like Stanford’s HELM, which includes over 15,000 instruction examples. That means if you ask it to “explain quantum computing like I’m 12,” “find the date in this contract,” or “write a polite rejection email,” it knows how to respond appropriately. According to Gartner’s January 2026 report, 87% of commercial LLM deployments now use instruction tuning. Why? Because users don’t want specialized tools-they want assistants. ChatGPT, Claude, and most enterprise chatbots rely on this method. JPMorgan’s instruction-tuned Llama2-13B model achieved 89.4% accuracy across 12 financial tasks while keeping 82.7% zero-shot performance on unseen ones. That’s the power of instruction tuning: it doesn’t just do what you trained it for-it adapts to what you didn’t. But instruction tuning isn’t easy. You need diverse, high-quality prompts. A 2025 study by GeeksforGeeks found data preparation costs are 30-40% higher than for task-specific tuning. You can’t just copy-paste questions from your support tickets. You need variations: different phrasings, edge cases, ambiguous inputs. And if you skimp on this, your model will be brittle. It’ll work fine on “What’s the capital of France?” but crash on “Tell me the capital of France, but pretend you’re a 10-year-old.” Training time is longer: 4-6 weeks. But you can cut that down with techniques like LoRA (Low-Rank Adaptation). Microsoft’s 2021 paper showed LoRA lets you tune a 7B model using only 0.1-1% of its parameters. That drops memory use from 80GB to 8-10GB. Suddenly, you’re not stuck needing a data center-just a single high-end GPU.
Performance Comparison: Accuracy, Speed, and Stability
Let’s break it down with real numbers.| Metric | Task-Specific Fine-Tuning | Instruction Tuning |
|---|---|---|
| Accuracy on Target Task | Up to 98.7% (e.g., ICD-10 coding) | 92-95% (e.g., financial document analysis) |
| Accuracy on Unseen Tasks | 60.9% | 83.2% |
| Training Time (GPU) | 12-48 hours | 72-120 hours |
| Implementation Time | 2-3 weeks | 4-6 weeks |
| Catastrophic Forgetting Risk | Up to 38% degradation | Under 5% with modular tuning |
| Memory Usage (7B model) | 80GB (full fine-tune) | 8-10GB (with LoRA) |
Hybrid Approaches Are the Future
The best of both worlds is here-and it’s called hybrid tuning. Meta’s January 2026 release of Llama3-70B-Instruct introduced “modular instruction tuning,” which lets you add task-specific adapters without breaking general abilities. The result? Only 4.2% performance drop on unrelated tasks, compared to 18.7% with traditional fine-tuning. This isn’t theoretical. JPMorgan’s team combined instruction tuning with a lightweight task-specific adapter for SEC filing classification. They kept 89.4% accuracy across all tasks and hit 94% on their primary goal. That’s the sweet spot: general capability with targeted precision. Companies like Nexla and Hugging Face are now offering tools that automate this process. You start with an instruction-tuned base model, then plug in a small adapter for your niche task. No retraining from scratch. No catastrophic forgetting. Just faster deployment and better results. OpenAI’s internal documents (verified by The Information, December 2025) show GPT-5 will use “dynamic instruction routing”-meaning the model will automatically decide whether to use its general knowledge or switch to a task-specific mode. That’s the endgame: one model, many modes.What’s Holding You Back?
The biggest barriers aren’t technical-they’re practical. For task-specific tuning: data quality. If your labeled examples are inconsistent or biased, your model will be too. In regulated industries, you also need audit trails. That means more time, more legal review, more cost. For instruction tuning: dataset diversity. You need prompts that cover edge cases, slang, typos, and ambiguous phrasing. A 2025 MLflow survey found 78% of users struggled with this. And yes, it takes longer to set up. But the payoff is worth it: instruction tuning tools have a 4.3/5 average rating on G2, compared to 3.8/5 for task-specific tools. And don’t ignore the environmental cost. MIT’s January 2026 study found instruction tuning uses 27% more energy than task-specific tuning. If your company has sustainability goals, that matters. But you can offset this with efficient techniques like LoRA and HINT (Hybrid Instruction Tuning), which reduce FLOPs by 2-4x.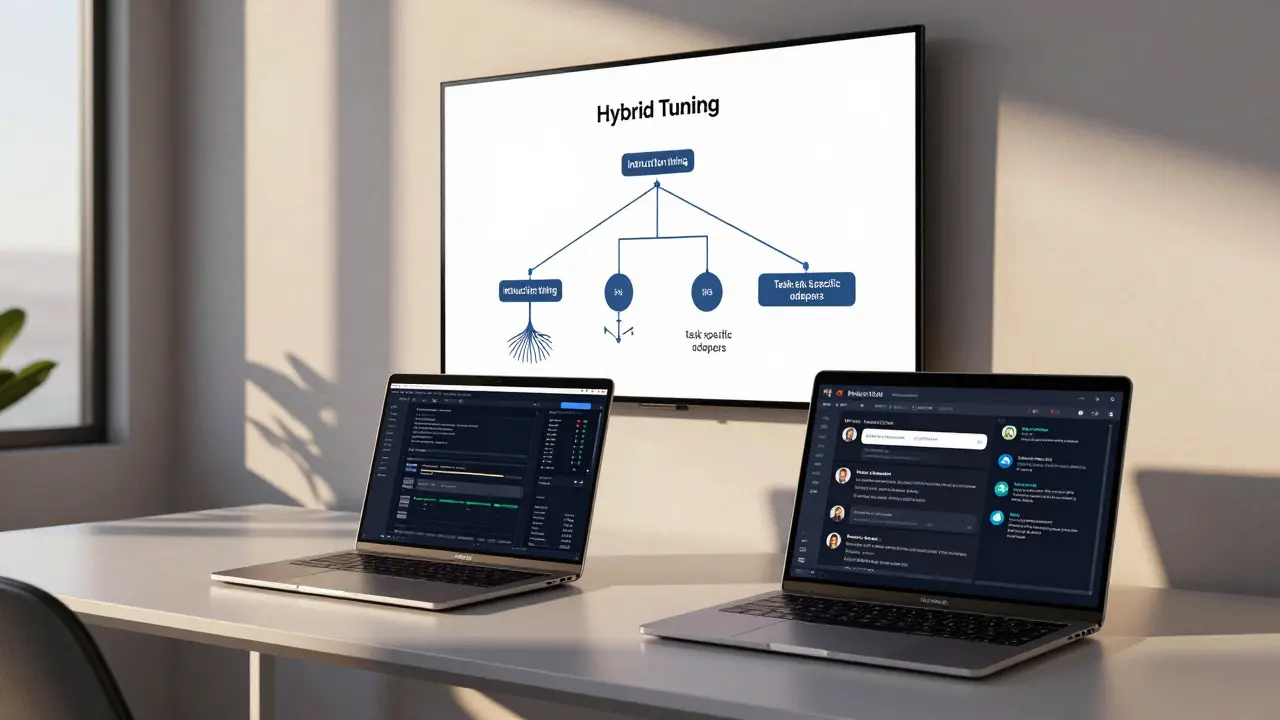
Which One Should You Choose?
Here’s a simple decision tree:- If you’re building a tool for one specific, high-stakes task (e.g., medical coding, fraud detection, SEC filing analysis) and users won’t ask anything else → go with task-specific fine-tuning.
- If you’re building a chatbot, assistant, or knowledge tool where users will ask unpredictable questions → instruction tuning is your only real option.
- If you need high accuracy on a core task but also want to handle other requests (e.g., a finance assistant that also drafts emails and summarizes reports) → use instruction tuning + a lightweight task-specific adapter.
Getting Started
Start with a pre-tuned model. Hugging Face’s Llama3-8B-Instruct is free, well-documented, and performs better than most custom models built on older frameworks. Use LoRA to fine-tune it with your own data. You don’t need a team of engineers-just a clear set of instructions and 1,000-2,000 labeled examples. If you’re in healthcare or finance, check out MergeKit. It’s an open-source tool that helps you combine instruction-tuned models with task-specific adapters without losing performance. It’s used by teams at Mayo Clinic and Bloomberg to reduce catastrophic forgetting by 41%. And remember: documentation matters. Hugging Face’s instruction tuning guides have a 4.5/5 satisfaction rating. Task-specific guides? Only 3.9/5. The community support is stronger for instruction tuning-14,328 Stack Overflow questions versus 8,742 for task-specific methods. You’re not alone.Final Thoughts
Instruction tuning isn’t just the trend-it’s the baseline. Task-specific fine-tuning isn’t obsolete-it’s a specialized tool. The future belongs to models that can be both general and precise. Start with instruction tuning. Add task-specific adapters only when you need that extra 5% accuracy. And always test on real user inputs-not just your training data. The right strategy isn’t about what’s newest or most powerful. It’s about what your users actually need.Can I use instruction tuning for a single task?
Yes, but it’s not optimal. Instruction tuning works best when you train on multiple tasks. If you only have one task, you’re wasting the model’s ability to generalize. You’ll get decent results, but task-specific fine-tuning will likely outperform it by 3-6% on that single task. Use instruction tuning for single tasks only if you plan to expand later.
Is LoRA enough for production use?
Absolutely. LoRA (Low-Rank Adaptation) is now standard in production. It reduces memory use by 90% compared to full fine-tuning, cuts training time, and preserves model performance. Companies like Hugging Face, AWS, and Google all recommend LoRA for instruction tuning in production environments. You don’t need to retrain the entire model-just the small adapter layers.
How much data do I need for instruction tuning?
You need at least 1,000-2,000 instruction-response pairs, but diversity matters more than volume. A dataset with 500 high-quality examples across 10 different tasks often outperforms 5,000 examples on just one task. Focus on covering variations: different phrasings, edge cases, and formats. Tools like OpenAI’s API or Hugging Face’s InstructLab can help you generate synthetic data to fill gaps.
What’s the biggest mistake people make with instruction tuning?
Using low-quality or repetitive prompts. Many teams copy-paste the same question with minor wording changes and call it “diverse.” That doesn’t work. Your model needs to see real human language-typos, ambiguity, incomplete sentences. If your training data looks like a textbook, your model will fail in the real world. Test your prompts with real users before training.
Can I switch from task-specific to instruction tuning later?
Yes, but it’s messy. If your model has suffered catastrophic forgetting, you’ll need to retrain from scratch or use a tool like MergeKit to combine your fine-tuned model with a base instruction-tuned model. The better path is to start with instruction tuning and add task-specific adapters as needed. That way, you keep your general abilities intact.
Are there free tools to try instruction tuning?
Yes. Hugging Face offers free access to instruction-tuned models like Llama3-8B-Instruct and tools like PEFT (Parameter-Efficient Fine-Tuning) and LoRA. You can fine-tune them on Google Colab with a free GPU. Start small: train on 500 examples, test on real prompts, then scale up. No need to spend money until you know it works for your use case.
Rajat Patil
January 19, 2026 AT 02:44Very clear breakdown. I work in healthcare IT and we went with task-specific tuning for ICD-10 coding. It worked great until we needed to summarize patient notes. Then we realized we’d lost everything else. Lesson learned.
deepak srinivasa
January 19, 2026 AT 06:28Interesting. So if I’m building a customer support bot that might get asked anything, instruction tuning is the way to go, even if it’s slightly less accurate on specific tasks?
pk Pk
January 19, 2026 AT 21:23Yes, absolutely. Start with instruction tuning. It’s like building a Swiss Army knife instead of a single screwdriver. You can always add a specialized blade later with adapters. We did this at my company-started with Llama3-Instruct, then added a tiny LoRA adapter for contract clause extraction. No retraining, no data loss. Magic.
NIKHIL TRIPATHI
January 20, 2026 AT 02:11I’ve seen teams waste months on task-specific tuning only to realize their users want to ask follow-ups. The model can’t handle it. Instruction tuning isn’t just better-it’s more human. People don’t want robots that do one thing perfectly. They want assistants that get them.
Also, LoRA is a game changer. I trained a 7B model on a 24GB GPU. Without it, I’d need a server farm. And the cost difference? Like choosing between a taxi and a private jet.
Just make sure your prompts are messy. Real people don’t speak in perfect sentences. If your training data looks like a textbook, your model will fail when someone types ‘whts the capitol of france?’
And yes, data prep takes longer. But it’s worth it. Our G2 score jumped from 3.1 to 4.6 after we fixed our prompt diversity.
Also, don’t ignore the environmental angle. Training a full fine-tune model uses more electricity than a small village in rural India uses in a week. LoRA cuts that by 80%. If your company cares about ESG, this isn’t optional.
Start small. Use Hugging Face’s free models. Try 500 examples. Test with real users. Then scale. No need to go all-in on day one.
And please, stop using ‘high-quality’ as a buzzword. Quality means diversity, not polish.
Shivani Vaidya
January 21, 2026 AT 11:02Hybrid approach makes sense. We tried pure instruction tuning for claims processing and the accuracy was 91%. Added a 100MB adapter for document classification and it jumped to 95.8% without losing general ability. No catastrophic forgetting. Just clean, modular upgrades.
anoushka singh
January 22, 2026 AT 02:15Wow, you all sound like you read the same blog post. Did you all get the same training data? Seriously, this is just a rehash of Hugging Face’s marketing page.
Jitendra Singh
January 22, 2026 AT 09:23Actually, I think Anoushka has a point. A lot of this feels like hype. But I’ve used both methods in production. Instruction tuning is more flexible. Task-specific is more accurate. Neither is perfect. The real answer is context.
Also, LoRA isn’t magic. If your base model is garbage, no adapter will save you.
Madhuri Pujari
January 22, 2026 AT 11:11Of course it’s hype! You’re all ignoring the real issue: data bias. You think your ‘diverse’ instruction set covers edge cases? You’ve trained on middle-class, English-speaking, tech-savvy users. What about elderly patients with limited literacy? Non-native speakers? People typing in Hinglish? Your model will fail them. And you call that ‘generalization’? Pathetic.
And don’t get me started on ‘free tools’-Hugging Face models are trained on scraped data that includes copyrighted material, abusive content, and toxic stereotypes. You’re building AI on a landfill. And you’re proud of it?
LoRA? It’s just a band-aid on a bullet wound. If you’re not auditing your training data at every step, you’re not building AI-you’re building a legal liability.
Sandeepan Gupta
January 23, 2026 AT 19:06Madhuri’s right about data bias-and that’s the real bottleneck. Most teams don’t have the resources to audit for dialects, cultural context, or accessibility. But that doesn’t mean you skip instruction tuning. It means you start smarter.
Use Hugging Face’s InstructLab to generate synthetic edge cases. Run your prompts through a tool like Fairlearn to detect bias. Test with real users from diverse backgrounds. Don’t assume your ‘typical’ user exists.
And yes, LoRA works. We used it to fine-tune a medical chatbot for rural India. We added 1,200 prompts in Hinglish with typos, slang, and incomplete sentences. Accuracy on real queries went from 68% to 92%. The model didn’t just learn-it adapted.
Start with instruction tuning. Fix your data. Add adapters only when needed. And never, ever trust a model trained on clean, textbook-style prompts.
AI isn’t about perfection. It’s about progress. And progress means listening to the people you’re trying to help-not just the benchmarks.