Large Language Models: Core Mechanisms and Capabilities Explained
 Jan, 8 2026
Jan, 8 2026
Large language models (LLMs) aren’t magic. They don’t understand language the way humans do. But they’re good enough at pretending to understand that they’re changing how we work, write, code, and even think. If you’ve used ChatGPT, Copilot, or Gemini, you’ve interacted with one. But what’s actually happening inside? How do these models turn a prompt into a coherent answer? And why do they sometimes get things wildly wrong?
How LLMs Process Language: From Words to Numbers
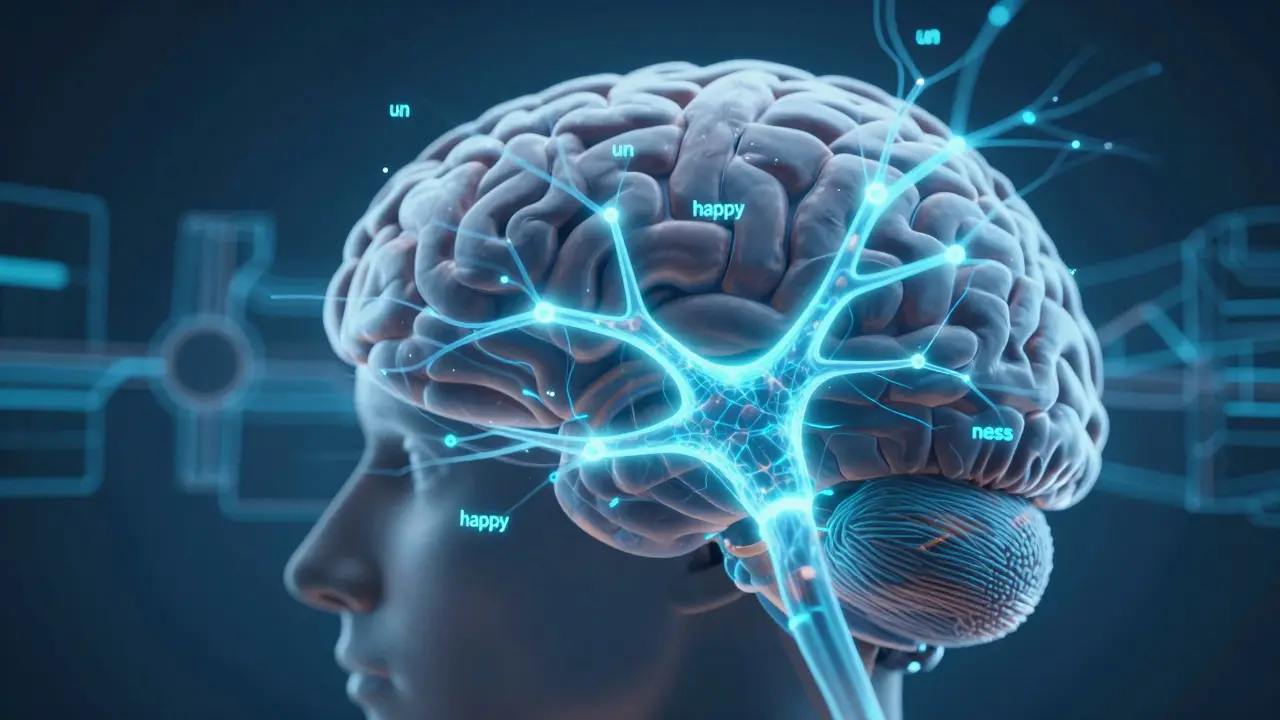
It all starts with breaking text into pieces. LLMs don’t read words like you do. They split text into smaller chunks called tokens. For example, the word "unhappiness" might become three tokens: "un", "happy", and "ness". This is done using a method called Byte Pair Encoding. It’s not random - it’s designed to handle common prefixes, suffixes, and word roots efficiently. Modern models use vocabularies between 32,000 and 100,000 tokens. That’s enough to cover most words you’ll ever type, without needing a separate token for every possible word in every language.
Once tokens are identified, they’re turned into numbers. Each token gets mapped to a vector - a list of hundreds or thousands of floating-point numbers. These vectors aren’t just labels; they encode meaning. The model learns that "king" and "queen" are close in this space, while "apple" and "run" are far apart. This is called an embedding layer. The size of these vectors depends on the model. Smaller models use 1,024 dimensions. The biggest ones go up to 8,192. More dimensions mean more nuance, but also more computing power.
The Transformer: The Engine Behind Everything
Before 2017, most language models used RNNs or LSTMs. These processed text one word at a time, like reading a book from left to right. That made them slow and bad at remembering what happened early in a long passage. The Transformer architecture, introduced in the paper "Attention Is All You Need," changed all that. Instead of processing tokens one after another, Transformers look at all of them at once.
The secret sauce is the attention mechanism. Imagine you’re reading this sentence: "The cat sat on the mat, which was black." You know "black" describes the mat, right? But what if the sentence was longer? What if there were 10 other objects? The attention mechanism lets the model ask: "Which parts of the input are most relevant to understanding this part?" It assigns weights - like focus levels - to every other token. So when processing "black," the model gives high attention to "mat," even if it’s 50 tokens away.
This happens in multiple "heads." A single Transformer layer might have 16, 32, or even 96 attention heads. Each head learns a different kind of relationship: one might track subject-verb pairs, another might link pronouns to nouns, another might notice repetition. The outputs from all heads are combined, giving the model a rich, multi-perspective understanding of context.
After attention, the data goes through a feedforward neural network. This is just a standard set of layered math operations that apply nonlinear transformations. It’s not fancy - it’s the same kind of thing used in image recognition. But together with attention, it lets the model learn complex patterns in language.
Model Scale: Why Bigger Is (Sometimes) Better
Size matters in LLMs - a lot. The number of parameters - the adjustable weights inside the model - determines how much it can learn. GPT-3 had 175 billion. PaLM 2 had 340 billion. Google’s Gemini Ultra is rumored to have over a trillion. More parameters mean the model can store more patterns, remember more context, and handle more complex tasks.
But it’s not just about raw size. There’s a rule of thumb: for optimal performance, you need about 20 tokens of training data per parameter. That means a 100-billion-parameter model needs 2 trillion tokens of text to train well. That’s equivalent to reading every book in a large university library - multiple times.
Training these models is expensive. A 100-billion-parameter model requires about 1,000 NVIDIA A100 GPUs running for 30 to 60 days. The cost? Between $10 million and $20 million. That’s why only big companies like Google, Meta, and Microsoft can afford to build the largest models from scratch.

Types of LLMs: Raw, Instruction-Tuned, and Dialog-Tuned
Not all LLMs are the same. There are three main types, each built for different jobs.
- Generic models - like GPT-2 - are trained only to predict the next word. They’re good at generating text that looks plausible, but they don’t follow instructions well. Ask them to summarize something, and they might just keep writing.
- Instruction-tuned models - like Flan-T5 - are fine-tuned on datasets where humans wrote prompts and expected answers. They learn to follow directions: "Write a poem," "Explain quantum physics," "Translate this to French." They’re the backbone of most AI assistants today.
- Dialog-tuned models - like ChatGPT or Claude 3 - are trained on conversations. They learn turn-taking, context retention, and how to handle follow-up questions. They remember what you said two messages ago. That’s why they feel more natural in chat.
Most models today start as generic, then get fine-tuned for instructions or dialogue. That’s why you can ask a model to "explain like I’m five" and it will adjust its tone - it’s been trained to recognize and respond to those cues.
Autoregressive vs. Masked: Two Ways of Predicting
There are two main ways LLMs predict text.
Autoregressive models - like GPT, Gemini, and Llama - predict the next token one at a time. Given "I like to eat," they guess the next word: "ice." Then they add "ice" to the input and guess the next word: "cream." This is how chatbots generate replies. It’s sequential, so it’s slower, but it’s great for open-ended generation.
Masked language models - like BERT - work differently. They’re shown a sentence with a word missing: "I like to [MASK] [MASK] cream." They predict both missing words at once: "eat" and "ice." This is better for understanding context, not generating text. BERT is used for search ranking, question answering, and sentiment analysis - tasks where you need to understand what’s already written.
Most modern LLMs are autoregressive because they’re better at conversation and content creation. But some, like Google’s PaLM 2, use a mix of both approaches.
What LLMs Can - and Can’t - Do
LLMs are powerful, but they’re not intelligent. They don’t know facts. They don’t reason logically. They predict what comes next based on patterns they’ve seen.
They’re great at:
- Writing emails, reports, and stories
- Summarizing long documents
- Translating between languages
- Generating code from a description
- Answering questions based on training data
But they struggle with:
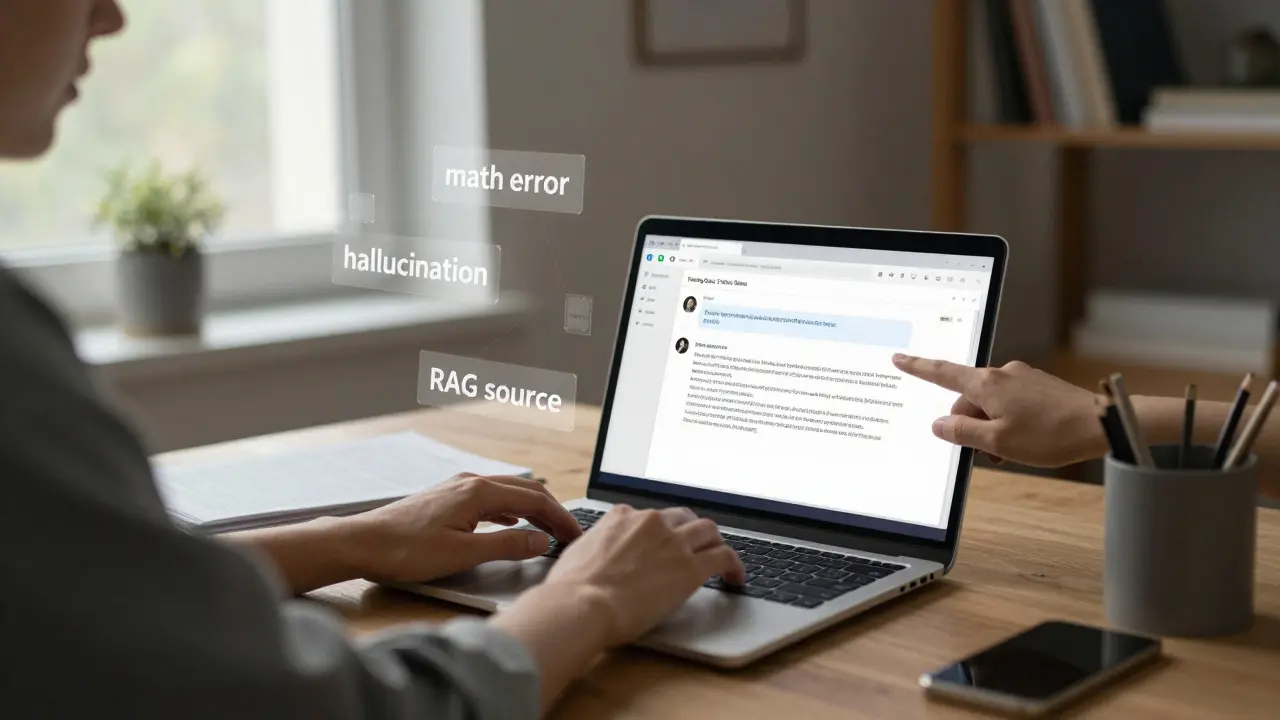
- Math - they often get simple arithmetic wrong because they’re guessing, not calculating
- Consistency - they might contradict themselves in a 10-sentence response
- Real-time knowledge - they don’t know what happened after their last training cut-off (usually 2023-2024)
- Hallucinations - they make up facts that sound real, like citing fake studies or inventing people
That’s why companies use techniques like Retrieval-Augmented Generation (RAG). Instead of relying only on what the model remembers, RAG pulls in real-time data from databases or documents. So when you ask, "What’s the latest FDA approval?" the model checks a live source first - then writes a response based on that.
Context Windows: The Memory Limit
Even the best LLM has a memory limit. That’s called the context window. It’s the maximum number of tokens the model can consider at once. Early models had 2,048 tokens - about 1,500 words. Now, models like Gemini 1.5 can handle up to 1 million tokens. That’s enough to read an entire book in one go.
But even with big windows, models still lose track. If you paste a 500-page PDF and ask a question about page 3, the model might focus on the last few pages. That’s why tools like RAG and chunking are important - they break long documents into pieces and retrieve the most relevant one.
What’s Next: Smaller Models, Multimodal, and Regulation
The biggest trend in 2025 isn’t bigger models - it’s smarter, smaller ones. Companies are building small language models (SLMs) with just 1 to 10 billion parameters. These can run on a laptop or phone. They’re not as flashy, but they’re 80% as capable as giants like GPT-4 - at 10% of the cost. Gartner predicts SLMs will dominate enterprise use by 2026.
Another shift is toward multimodal models. Llama 3 and Gemini 1.5 can now process images, audio, and video along with text. You can upload a screenshot of a spreadsheet and ask, "What’s the trend here?" The model analyzes the image, reads the numbers, and gives you an answer.
And regulation is catching up. The EU AI Act, which takes full effect in 2025, classifies LLMs as high-risk if used in hiring, law enforcement, or public services. Companies must now document training data, test for bias, and allow human oversight. Transparency is no longer optional.
Final Thoughts: Tools, Not Thinkers
Large language models are tools - powerful, fast, and sometimes surprising. But they’re not thinking. They’re pattern-matching on a massive scale. Understanding how they work helps you use them better. Don’t trust them blindly. Don’t assume they’re right. Ask for sources. Check the math. Use RAG when accuracy matters. And remember: the best results come from pairing human judgment with machine speed.
How do large language models learn to understand language?
LLMs learn by analyzing massive amounts of text - billions of sentences from books, websites, and code. They don’t memorize answers. Instead, they learn statistical patterns: which words usually follow others, how grammar works, how tone changes in different contexts. The transformer architecture helps them connect distant parts of text using attention, so they can grasp relationships like subject-verb agreement or pronoun references across long passages.
Why do LLMs sometimes make things up?
LLMs don’t have access to real-world facts. They predict the most likely next word based on training data. If the training data contains a false claim that sounds plausible - like a fake study or a made-up quote - the model may repeat it because it fits the pattern. This is called hallucination. It’s not lying; it’s guessing. Using Retrieval-Augmented Generation (RAG) helps reduce this by grounding responses in verified sources.
What’s the difference between GPT and BERT?
GPT is autoregressive - it predicts the next word one at a time, making it great for generating text like stories or replies. BERT is masked - it fills in missing words from both sides of a sentence, making it better for understanding meaning, like answering questions or classifying sentiment. GPT generates; BERT interprets.
Can I run a large language model on my own computer?
You can run smaller versions - like Llama 3 8B or Mistral 7B - on a high-end PC with a powerful GPU. But full-sized models like GPT-4 or Gemini Ultra require hundreds of GPUs and massive memory. For most people, using cloud APIs (like OpenAI or Anthropic) is the practical choice. Open-source models like Llama 3 let you experiment locally, but training them from scratch still needs enterprise-grade hardware.
How are companies using LLMs today?
Sixty-seven percent of Fortune 500 companies use LLMs for at least one task. Common uses include automating customer service with chatbots, summarizing legal or medical documents, generating marketing copy, writing code snippets, and analyzing customer feedback. Some use them for internal knowledge search - uploading manuals or policies so employees can ask questions like "What’s the vacation policy?" - without digging through files.
What’s the environmental impact of training LLMs?
Training a single large model can use as much electricity as five homes consume in a year. A 100-billion-parameter model running on 1,000 A100 GPUs for 45 days may emit over 100 metric tons of CO₂ - equivalent to driving a car 250,000 miles. That’s why researchers are focusing on efficiency: model pruning, quantization (reducing precision of numbers), and distillation (training smaller models to mimic larger ones). The goal is to get 80% of the performance with 10% of the energy.
Diwakar Pandey
January 8, 2026 AT 14:11Really liked how you broke down tokens and embeddings. I always thought LLMs just memorized stuff, but the way they map meaning into vectors is wild. BPE is genius for handling compound words without blowing up the vocab.
Geet Ramchandani
January 10, 2026 AT 05:42Ugh another overhyped tech article. These models don’t understand anything. They’re just fancy autocomplete with a billion parameters and zero common sense. People act like they’re sentient when they can’t even do basic math without hallucinating a fake answer. It’s embarrassing how much money we’re throwing at this.
Pooja Kalra
January 10, 2026 AT 17:25Is it not profound that we’ve outsourced meaning to statistical noise? The transformer doesn’t know truth-it only knows recurrence. We project consciousness onto patterns, mistaking familiarity for understanding. Language, once a vessel of human spirit, now flows through the hollow channels of probability. What have we become, when our mirrors speak back in fluent gibberish?
Jeroen Post
January 12, 2026 AT 09:48They’re not even models they’re surveillance tools trained on stolen data from every website you ever visited. The government and Big Tech are using this to shape thought. You think ChatGPT is helping you write? It’s conditioning you. And don’t get me started on how they scrub dissent from training data
Nathaniel Petrovick
January 14, 2026 AT 09:38Yea this is solid. I use Copilot daily and honestly the attention mechanism thing clicked for me when I saw it pick up on a variable name from 20 lines up. Kinda mind blowing how it just knows what’s relevant. Also the part about SLMs running on laptops? That’s the future right there.
Honey Jonson
January 15, 2026 AT 09:35OMG yes!! I love how you explained RAG and context windows. I tried pasting my whole thesis into Gemini once and it just forgot half of it lol. And the part about small models being 80% as good? I’m so done with needing a supercomputer to run a chatbot. My laptop can handle Mistral now and it’s fine 😌
Sally McElroy
January 15, 2026 AT 14:35While I appreciate the technical depth, I must emphasize: this article dangerously underplays the existential risk of anthropomorphizing machines. LLMs are not tools-they are linguistic ghosts, echoing human expression without moral grounding. The normalization of hallucinations as ‘predictive error’ is ethically negligent. We must demand accountability, not convenience.
James Winter
January 17, 2026 AT 00:28US and China are wasting billions on AI while our infrastructure crumbles. These models can’t even spell ‘their’ right half the time. We need real jobs, not chatbots pretending to be smart.