Pipeline Orchestration for Multimodal Generative AI: Preprocessors and Postprocessors Explained
 Jul, 6 2025
Jul, 6 2025
Imagine you’re asking an AI to describe a video of a child laughing while holding a dog, with background music playing and someone saying, "Look at them go!" The AI doesn’t just see the video, hear the audio, or read the text-it has to understand all of it together. That’s where pipeline orchestration comes in. Without it, the AI would process each piece of data separately, like trying to solve a puzzle with half the pieces missing. Pipeline orchestration is the invisible system that makes sure every input-text, image, audio, video-gets cleaned, aligned, and fed into the model at the right time, in the right way.
Why Preprocessors Are the Unsung Heroes
Before any multimodal AI model can work, the data has to be ready. Raw video files? Too big. Audio clips with background noise? Too messy. Text from different sources? Inconsistent formats. This is where preprocessors step in. They’re the first line of defense against chaos. NVIDIA’s NeMo Curator, for example, uses a 3D wavelet downsampling technique that shrinks video data by 4.7 times without losing detail. That’s not just a technical trick-it means you can process 7x faster than other systems. In security surveillance, one company cut video processing time from hours to minutes. That’s the difference between spotting a threat in real time or finding out hours later. Microsoft’s approach is different. They use something called a medallion lakehouse: bronze, silver, gold layers. Raw data lands in bronze. Then, preprocessors clean it up, match formats, and fix timestamps in silver. Finally, in gold, they turn it into structured feature stores-ready for the AI to use. In healthcare, this reduced redundant API calls by 62%. That’s not just efficiency; it’s compliance. HIPAA requires strict data handling, and this architecture makes it possible. Preprocessors don’t just shrink files. They fix alignment. If a video frame is 0.3 seconds ahead of the audio, the AI gets confused. NVIDIA’s causal structure fixes this by only letting the model use past and current frames-no peeking into the future. That small rule cuts errors by up to 22% in joint audio-video tasks.Postprocessors: Turning AI Output Into Action
The AI model spits out a jumble of numbers, probabilities, and embeddings. That’s not useful to a human or a system. Postprocessors turn that into something meaningful. There are three main ways to combine multimodal outputs: early, mid, and late fusion. Early fusion merges data before the model even sees it-like blending text and image into one input stream. It’s fast and used in 87% of vision-language tasks. But if one modality is noisy, it drags everything down. Mid-fusion keeps data separate longer, combining them in the middle layers of the model. It’s common in medical imaging, where doctors need to cross-reference X-rays with patient notes. Here, 43% of systems use this method because it preserves context. Late fusion waits until the end. Each modality gets its own output, then they’re weighed and combined. This is the go-to for customer service chatbots. If a user sends a photo of a broken product and says, "This arrived damaged," the system checks the image quality, reads the text, and listens for tone in voice messages (if available). Late fusion gives 28% better accuracy here-but uses 41% more computing power. Zilliz’s Milvus vector database handles this at scale. It can process 18,400 embeddings per second on a single AWS p4d.24xlarge instance. That’s 7.3x faster than basic GPU setups. For companies handling millions of customer interactions daily, that speed isn’t optional-it’s survival.Frameworks Compared: NeMo, Microsoft, Zilliz, CrewAI
Not all orchestration tools are built the same. Here’s how the top players stack up:| Framework | Best For | Key Strength | Weakness | Enterprise Readiness (Gartner) |
|---|---|---|---|---|
| NVIDIA NeMo 2.0 | Visual and video processing | 7x faster video processing, wavelet compression | Steeper learning curve, less flexible for text-heavy tasks | 4.3/5 |
| Microsoft Orchestrate | Healthcare, regulated industries | HIPAA-compliant medallion architecture, FHIR integration | Complex metadata handling, 63% of users report inconsistencies | 4.1/5 |
| Zilliz / Milvus | Retrieval-augmented generation (RAG) | 92.4% precision at scale, real-time CDC sync | Less mature for real-time video/audio | 4.0/5 |
| CrewAI 0.32 | Open-source prototyping | Role-based agents, active community | Weak security, 3.2/5 on enterprise readiness | 3.2/5 |

What You Need to Run This
You can’t run multimodal orchestration on your laptop. The hardware demands are real:- GPUs: NVIDIA A100 (minimum 40GB VRAM). Anything less slows down preprocessing and causes bottlenecks.
- RAM: 100+ GB for large-scale deployments. You’re not just storing data-you’re holding embeddings, metadata, and temporary fusion states.
- Storage: NVMe drives with at least 3.5GB/s throughput. Multimodal pipelines ingest 2.8TB of data per hour. If your disk can’t keep up, the whole system stalls.
- Software: Python (used in 87% of systems), PyTorch or TensorFlow (76%), and distributed systems knowledge (63%). You’re not just coding-you’re managing data flow across servers.
The Hidden Costs and Risks
This isn’t magic. It’s engineering-and it comes with trade-offs. The biggest problem? Modality impedance mismatch. That’s a fancy way of saying: different data types don’t play nice. A 30-second video with 15-second audio? The AI gets confused. A text description written after the video was recorded? Timestamps drift. This causes 15-22% errors in joint processing. MIT’s lab found that 68% of enterprise pipelines need 3-5 specialized engineers just to keep them running. That’s expensive. And it’s not just headcount-it’s the time spent debugging. Stack Overflow users say 74% of their time goes into tracing where a pipeline broke. Was it the preprocessor? The fusion layer? The metadata mismatch? It’s like untangling Christmas lights. Then there’s the complexity cliff. Add one more modality-say, thermal imaging or EEG brainwave data-and pipeline complexity jumps by 3.2x. Most systems start to break around 5-6 modalities. That’s why companies are already looking toward orchestration-as-a-service. By 2026, 67% of enterprises plan to outsource this to managed platforms like Azure AI Studio or NVIDIA’s cloud offerings.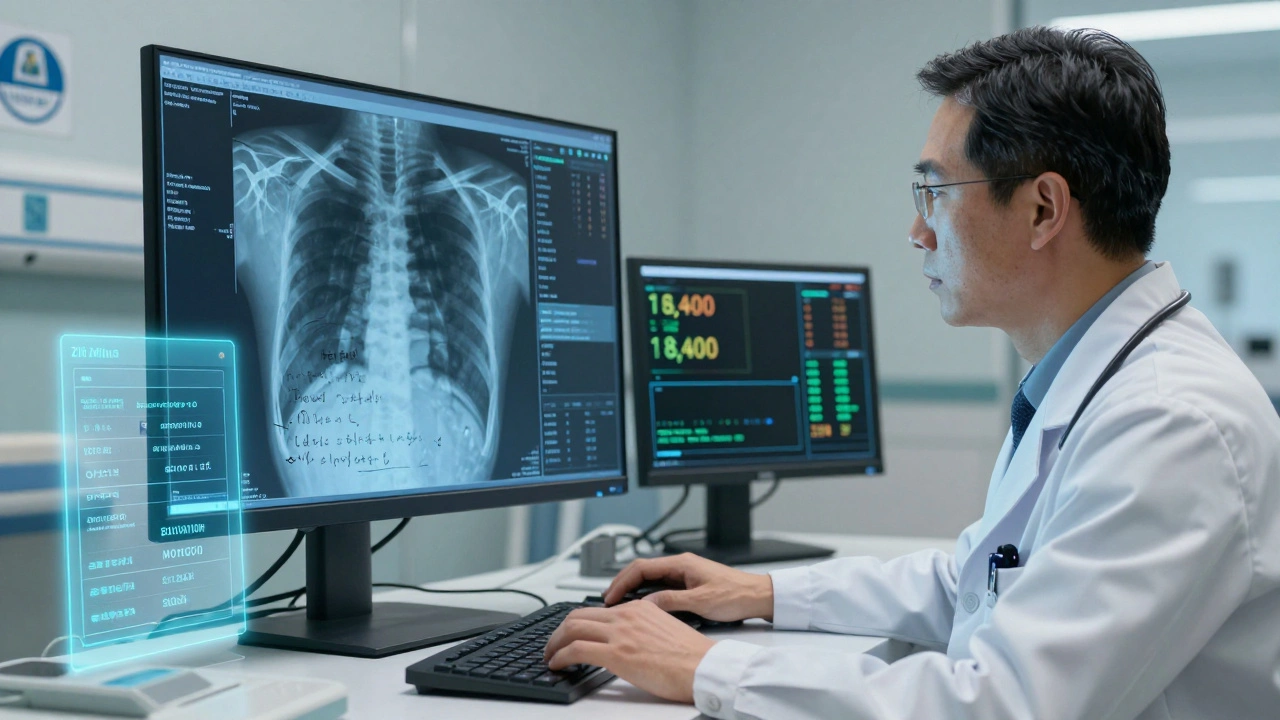
What’s Next?
NVIDIA’s NeMo 2.1 (coming Q1 2025) will auto-adjust preprocessing based on what the AI needs next. If the model is doing facial recognition, it’ll keep high-res images. If it’s just detecting motion, it’ll compress harder. That’s adaptive intelligence. Microsoft is folding its orchestration tools directly into Azure AI Studio. That means developers won’t need to stitch together separate systems-they’ll get it built-in. The market is exploding. Valued at $2.8 billion in late 2024, it’s expected to hit $14.7 billion by 2027. Healthcare, retail, and security are leading adoption. But the real winners will be the ones who solve the alignment problem-not just the ones with the fastest GPUs.Frequently Asked Questions
What’s the difference between preprocessors and postprocessors in multimodal AI?
Preprocessors clean and prepare raw data-like resizing images, syncing audio to video, or normalizing text-before it enters the AI model. Postprocessors take the AI’s raw output (embeddings, probabilities) and turn it into usable results, like summaries, labels, or actions. Think of preprocessors as the chef prepping ingredients, and postprocessors as the waiter serving the meal.
Why can’t I just use one model for all data types?
Multimodal models like GPT-4o can handle text, images, and audio together, but they still need clean, aligned inputs. Raw data is messy. A 4K video file is 100x larger than a text prompt. Audio has background noise. Text has typos. Without preprocessors, the model wastes time and accuracy on bad data. Postprocessors ensure the output is useful-not just technically correct.
Is open-source like CrewAI good enough for business use?
CrewAI is great for prototyping and small projects. It’s flexible, has a strong community, and is free. But for enterprise use-especially in healthcare, finance, or security-it falls short. It lacks built-in compliance (HIPAA, GDPR), has weak security controls, and scores only 3.2/5 on enterprise readiness. For production systems, you need the structure, support, and compliance of NVIDIA NeMo or Microsoft’s framework.
How do I know which fusion method to use-early, mid, or late?
Use early fusion if speed matters and data is clean-like tagging social media posts with images. Use mid-fusion if context is critical-like analyzing X-rays with doctor notes. Use late fusion when accuracy is non-negotiable and you have the compute power-like customer service chatbots that combine voice, text, and video. Late fusion is slower but more accurate, especially when inputs are noisy or incomplete.
What’s the biggest mistake companies make when building these pipelines?
They focus too much on the AI model and ignore the data pipeline. A state-of-the-art model with bad inputs gives bad results. The biggest failure isn’t technical-it’s organizational. Teams don’t align on metadata standards. Timestamps aren’t tracked. File formats change without notice. The pipeline breaks because no one owns the data flow. Fix the process before you optimize the code.
mark nine
December 10, 2025 AT 03:53Preprocessors are the real MVPs here. I've seen teams waste months on models that just needed better timestamp sync. No fancy architecture fixes bad data. Just clean it first and move on.
Tony Smith
December 11, 2025 AT 21:47One must, with the utmost gravity, acknowledge that the structural integrity of multimodal pipelines is not merely an engineering concern-it is a metaphysical imperative. The data, in its raw state, is a cacophony of chaos; only through the divine orchestration of preprocessing can we ascend toward the sublime harmony of machine understanding.
Chris Atkins
December 12, 2025 AT 16:47Been running NeMo on a few security cams and it's crazy how much faster things go. Used to take 4 hours to process a day's feed, now it's under 30 mins. No hype, just works. Also, don't even get me started on how much easier it is than trying to glue together Microsoft's medallion thing
Jen Becker
December 12, 2025 AT 17:15So you're telling me we're paying millions so AI can watch kids laugh and not glitch out? We're doomed.
Rob D
December 13, 2025 AT 18:22USA built this. NVIDIA, Microsoft, Zilliz-all American tech. China's still trying to copy the preprocessing step. They don't even know what a wavelet is. We don't need to outsource this. We built the future. Now we just gotta make sure the libs don't get their hands on it.
Franklin Hooper
December 14, 2025 AT 08:02There is a misplaced comma in the sentence 'That’s not just efficiency; it’s compliance.' The semicolon is correct, but the phrase 'it’s compliance' lacks a subject complement. One might argue it implies 'it is compliance'-but compliance with what? The sentence is structurally incomplete. Also, 'medallion lakehouse' is not a recognized term in data architecture literature. It is a marketing neologism.
Jess Ciro
December 14, 2025 AT 11:15They're not fixing pipelines. They're building a surveillance state. Every timestamp synced, every frame aligned-it's all to track you. That 22% error reduction? That's the government finally getting the video and audio to match your face with your voice. Next thing you know, your dog's bark gets flagged as a threat. Wake up.