Retrospectives for Vibe Coding: How to Learn from AI Output Failures
 Feb, 2 2026
Feb, 2 2026
Why Vibe Coding Needs Its Own Kind of Retrospective
You’ve probably heard of Vibe Coding-where you let AI write code, then check if it works instead of reading every line. It’s fast. It feels magical. But when the AI generates a financial calculation that’s off by 20%, or a security loophole that slips through, you can’t just fix the bug and move on. You need to understand why it happened. That’s where retrospectives come in-not the kind you do after a sprint, but a new kind designed for AI mistakes.
Traditional retrospectives ask: "Did we communicate well?" or "Were our deadlines realistic?" Vibe Coding retrospectives ask: "What did the AI misunderstand?" and "Why did our prompt fail to get it right?" These aren’t just fixes. They’re lessons that build your team’s collective memory about how AI thinks-and where it trips up.
The Four Failure Zones in AI-Generated Code
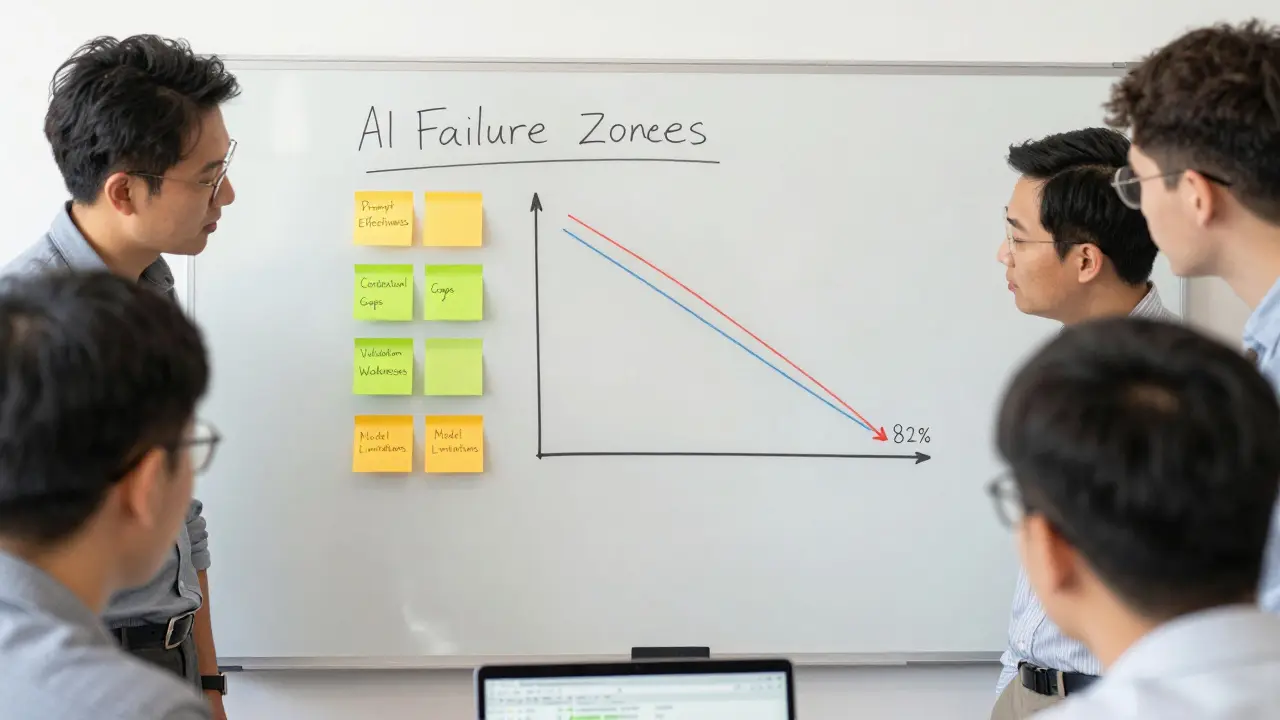
Not all AI mistakes are the same. The Vibecoding Alliance tracked over 342 incidents and broke them into four clear patterns:
- Prompt effectiveness (47% of failures): Your instruction was too vague. "Make a login form" isn’t enough. Did you specify error handling? Password rules? Session timeout? The AI fills in the blanks-with wrong assumptions.
- Contextual understanding gaps (29%): The AI didn’t know your system’s rules. Maybe your app uses a custom auth library, or your database has unique constraints. The AI didn’t ask for clarification because it wasn’t trained to.
- Validation weaknesses (15%): You trusted the output too much. The code ran without errors, but the logic was flawed. No test caught it because you didn’t write one for that edge case.
- Model limitations (9%): The AI just didn’t know how to do it. Sometimes, it’s not your fault-it’s a known gap in the model’s training data.
Teams that track these patterns over time start to see trends. One team noticed their AI kept misinterpreting "user role" as "user type" because their documentation used both terms interchangeably. They standardized the language-and cut that failure type by 82% in two months.
The 7-Part Retrospective Template That Works
Ad-hoc fixes don’t scale. You need structure. The Supervised Vibe Coding Methodology recommends a 7-section retrospective template, used by over 400 organizations as of early 2026:
- Prompt Reconstruction: Write down the exact prompt you used. Not "I asked for a payment processor." But: "Generate a Python function that accepts a USD amount, applies a 2.9% fee, and returns net amount in cents. Use the Stripe API v2023-08-16. Handle partial refunds. Return error if currency is not USD."
- Error Classification: Pick one of the 12 failure types from the Vibecoding Alliance’s list. Don’t guess. Use the official taxonomy.
- Validation Gap Analysis: What test should have caught this? Was it missing? Was it too broad? Did you rely on manual checking?
- Human Oversight Effectiveness: Did someone review it? Who? Did they understand what they were looking at? Or did they just click "deploy" because it "looked right"?
- Contextual Understanding Assessment: Did the AI have access to the right docs? Codebase? Environment variables? Was there a missing context window?
- Corrective Action Plan: One clear action item per person. Not "improve prompts." But: "Sarah will update the prompt template to include API version and error handling requirements by Friday."
- Process Improvement Metrics: How will you measure success? Track the same failure type next month. Did it drop? By how much?
Teams that use this template religiously reduce repeat failures by 63% compared to those who just talk about it in standups. The key? Writing it down. Not just talking. Documenting. Making it visible.
Real Stories: What Happens When You Do It Right
DevOpsDave42, a developer at a fintech startup, posted on Reddit after their AI-generated payment logic caused a $12,000 overcharge. Instead of blaming the AI, they ran a full retrospective. They discovered the prompt didn’t mention currency conversion rules, and the validation step only checked if the number was positive-not if it matched the customer’s actual balance.
They updated their prompt template to require: "Include currency validation against customer profile. Use only USD unless explicitly overridden by customer settings. Log all conversion decisions." They added a unit test that simulated 500 currency mismatches. Within four months, that exact failure never happened again.
Another team at a healthcare startup used the same template after an AI-generated patient scheduling tool sent duplicate appointment reminders. They found the AI had reused a generic calendar function from open-source code that didn’t account for their clinic’s 15-minute buffer rule. The fix? They added a new context file to their AI’s input-listing all clinic-specific rules-and now it’s part of every new prompt.
Why Most Teams Fail at This (And How to Avoid It)
It’s not hard to run a retrospective. It’s hard to make it matter. Here’s what goes wrong:
- Blame the person: "You wrote a bad prompt." That shuts down learning. Focus on the prompt, not the person.
- No logs: If you don’t save the prompt and the AI’s response, you can’t analyze it later. Teams that log every interaction reduce repeat errors by 68%.
- No action owner: "We’ll fix this next time" means it never gets fixed. Assign a name. A deadline. A metric.
- Skipping Phase 1: Many teams jump straight into retrospectives without learning the 12 failure types first. You can’t classify what you don’t know. Spend a week studying the patterns.
One developer told the arXiv survey team: "I don’t need to understand the AI’s mistakes-just fix the code." That’s the mindset that keeps teams stuck. Vibe Coding isn’t about outsourcing thinking. It’s about upgrading your attention.

The Bigger Picture: Retrospectives as AI Training Fuel
This isn’t just about fixing bugs. It’s about teaching your AI.
Google’s "Project Reflex," launched in January 2026, takes every retrospective report from internal teams and feeds it back into their coding model. After three months, specific failure types dropped by up to 74%. The AI learned what prompts lead to what mistakes-and adjusted its internal logic to avoid them.
That’s the future: retrospectives aren’t just post-mortems. They’re training data. Every time you document a failure, you’re helping the AI become better-not just for you, but for everyone using it.
And it’s not just Google. The Vibecoding Alliance updated their template on February 1, 2026, adding two new sections: "Security Vulnerability Pattern Tracking" and "Regulatory Compliance Impact." Why? Because financial and healthcare teams are being fined for AI mistakes they didn’t document. Retrospectives are becoming compliance tools.
What Comes Next?
By 2027, Gartner predicts 85% of companies using AI for code will have formal retrospective frameworks. Right now, only 47% do. The gap is closing fast.
Tools like GitHub Copilot Enterprise’s "AI Incident Analyzer" and "VibeInsight" now auto-suggest retrospective templates based on past failures. Microsoft’s "RetrospectAI" prototype cuts analysis time by 62% by auto-summarizing logs and flagging patterns.
But the real win isn’t the tool. It’s the culture. Teams that treat AI failures as learning moments-not embarrassments-improve their AI collaboration speed 3.2x faster than those who don’t. That’s not magic. That’s discipline.
Think of it this way: unit tests used to be optional. Now they’re mandatory. In five years, AI output retrospectives will be the same. The question isn’t whether you’ll do them. It’s whether you’ll start before you get burned.
What’s the difference between a regular retrospective and a Vibe Coding retrospective?
Regular retrospectives focus on team communication, sprint planning, or workflow bottlenecks. Vibe Coding retrospectives focus on AI-specific failures: how your prompt was written, what the AI misunderstood, why your validation missed the error, and how to prevent it next time. It’s not about people-it’s about patterns in AI behavior.
Do I need special tools to run Vibe Coding retrospectives?
No, you can start with a simple document or spreadsheet. But tools like GitHub Copilot Enterprise’s AI Incident Analyzer, or the open-source vibe-retrospective-templates on GitHub, make it faster and more consistent. The key isn’t the tool-it’s the discipline of documenting prompts, failures, and fixes every time.
How often should we run these retrospectives?
Run one after every major AI-generated code merge or production incident. The Vibecoding Alliance recommends completing analysis within 48 hours while the context is still fresh. Don’t wait for a sprint review. If the AI broke something, analyze it within a day.
Can retrospectives make AI less reliable?
No-they make AI more reliable over time. Each retrospective adds data that helps you write better prompts and catch failures earlier. Some teams even feed their retrospective logs back into their AI models to retrain them, reducing future errors by up to 74%. It’s not about limiting AI-it’s about guiding it.
What if my team resists doing retrospectives?
Start small. Pick one recurring failure-say, AI misreading a database schema-and run a single retrospective on it. Show the team how much time it saved next time. People resist when they think it’s busywork. They embrace it when they see it actually makes their job easier.
Are there security risks in Vibe Coding retrospectives?
Yes-if you log prompts with sensitive data like API keys, user IDs, or internal endpoints. Always sanitize logs before storing them. The updated Vibecoding template now includes a "security vulnerability pattern tracking" section to help teams spot these risks. Never store raw prompts in plain text. Use encrypted logs or redacted templates.
Madhuri Pujari
February 2, 2026 AT 09:47Sandeepan Gupta
February 3, 2026 AT 20:30Tarun nahata
February 4, 2026 AT 02:59Aryan Jain
February 5, 2026 AT 01:48Nalini Venugopal
February 5, 2026 AT 02:53Pramod Usdadiya
February 6, 2026 AT 03:34Jen Deschambeault
February 6, 2026 AT 15:12