Scaling AI: Playbooks for RAG, Agents, and Prompt Engineering
 Apr, 14 2026
Apr, 14 2026
The RAG Architecture: Moving Beyond Simple Retrieval
Retrieval-Augmented Generation, or RAG is an architectural pattern that fetches relevant data from an external knowledge base to provide an LLM with factual context before it generates a response, is the backbone of most enterprise AI. But basic RAG is often too blunt for scale. A production-ready pipeline requires a more granular approach.
A high-impact RAG system typically consists of four primary stages:
- The Encoder: This is where your query is turned into a vector. Using transformer-based models, the encoder ensures the system understands the semantic meaning of a question, not just the keywords.
- The Retriever: This component scans vector stores like Pinecone, FAISS, or Weaviate to find the top-matching document chunks.
- The Generator: The LLM that takes the retrieved text and the original prompt to craft the final answer.
- Post-processing: This is the secret sauce for scale. It involves re-ranking the retrieved results to ensure the most relevant piece of information is at the top before the LLM ever sees it.
One of the biggest pitfalls in RAG is arbitrary chunking. Instead of splitting a document every 500 characters, use single-topic chunking. This means organizing your data around individual concepts, which allows the retriever to grab a precise answer rather than a fragment of a sentence and a bit of unrelated text.
| Technique | Benefit | Cost/Trade-off |
|---|---|---|
| Query Rewriting | Higher retrieval accuracy | Increased token spend (higher latency) |
| Reranking Stage | Reduced hallucinations | Added computational overhead |
| Few-Shot Learning | Better formatting/tone | Consumes more context window |
Designing Goal-Driven AI Agents
Once you have reliable data retrieval, the next step is agency. An AI Agent is a system that can plan, use tools, and iterate on its own work to achieve a specific goal. Scaling agents is harder than scaling RAG because the potential for "looping" or logic errors increases exponentially.
To build agents that actually earn trust, follow a three-pillar design philosophy: clarity, verification, and discipline. You don't just give an agent a goal; you give it a framework for planning. This means the agent should first draft a plan, execute a step, verify the result against a set of constraints, and then adjust its next move.
The shift we're seeing in 2026 is the move toward context engineering. While prompt engineering was about finding the "magic words," context engineering is about managing the entire environment the agent lives in. This involves deciding exactly what information is needed for a specific task and stripping away the noise to prevent the model from getting distracted by irrelevant data.
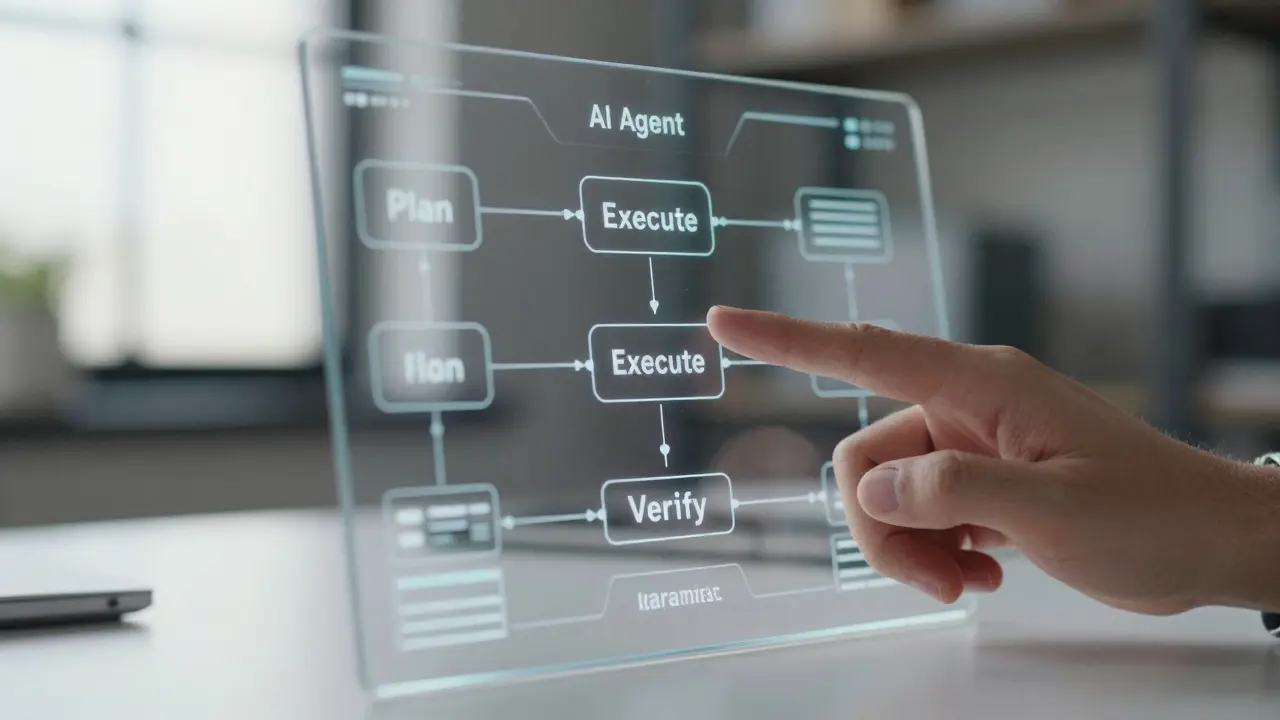
The Great Divide: Prompt vs. Knowledge Base
A common mistake is stuffing everything into the system prompt. When your prompt becomes a 10-page document, you encounter "prompt bloat," where the model ignores instructions in the middle of the text and latency spikes. The solution is a strict delineation of responsibilities.
Think of it as the difference between a script and a library. Your Prompt should be the script: it defines the personality, the tone, the decision rules, and the non-negotiable guardrails (like disclaimers). If a rule must be followed 100% of the time, it stays in the prompt.
Your Knowledge Base is the library. This is for the detailed, dynamic content-product manuals, regional pricing, or evolving company policies. By keeping the prompt lean and the knowledge base structured, you can update your company's policies in the vector store without having to re-test and redeploy your entire agent's personality layer.
Prompt Engineering at Scale
In a production environment, you cannot manually tweak prompts for every single user interaction. You need a systematic way to optimize. The most effective method currently is In-Context Learning (ICL), which uses few-shot examples to show the model exactly what a "good" answer looks like.
For complex reasoning, employ Chain-of-Thought (CoT) and Reflection. Instead of asking for a direct answer, force the model to "think out loud" and then review its own logic. For example, an agent processing a legal contract should first list the clauses it finds, then analyze each one, and finally provide a summary. This transparency makes it much easier to debug when something goes wrong.
However, be mindful of the token budget. Advanced techniques like query rewriting (where an LLM transforms a user's vague question into a search-optimized query) significantly improve performance but increase costs. The rule of thumb is to start with the simplest prompt possible and only add complexity where your evaluation metrics show a failure.

Operationalizing the AI Lifecycle
RAG and agentic systems are not "set and forget" software. They are living organisms that drift over time. To maintain a production system, you need a rigorous LLM operations (LLMOps) strategy.
First, treat your RAG pipeline as a series of independent components. Benchmark the retriever and the generator separately. If your agent is giving wrong answers, you need to know if the retriever failed to find the right document or if the generator failed to interpret it. If the retriever is the problem, you fix your chunking or embedding model; if the generator is the problem, you fix your prompt.
Second, implement smart caching. Many users ask the same set of "hot" questions. Caching these responses with sensible expiration settings reduces your compute costs and slashes latency for the end user.
Finally, establish a continuous feedback loop. Monitor for error spikes and drift. Because LLM providers occasionally update their underlying models, a prompt that worked perfectly in January might behave differently in April. Regular regression testing against a golden dataset of expected inputs and outputs is the only way to ensure stability at scale.
What is the difference between prompt engineering and context engineering?
Prompt engineering focuses on the specific phrasing, keywords, and instructions given to an LLM to get a desired output. Context engineering is a broader architectural approach that focuses on what data is presented to the model, how it is structured, and how it is retrieved from external sources to optimize the model's environment for accuracy and efficiency.
Should I use a vector database or just put everything in the prompt?
If your data is small and static, the prompt is fine. But for scale, you need a vector database. Putting too much in the prompt leads to "prompt bloat," increasing costs and causing the model to ignore instructions. A vector database allows the agent to fetch only the most relevant snippets of information on demand.
What is 'single-topic chunking' in RAG?
Single-topic chunking is the practice of breaking down documents based on logical thematic boundaries rather than fixed character or token counts. This ensures that each chunk contains a complete thought or fact, preventing the retriever from returning fragmented or irrelevant text that confuses the generator.
How do I reduce hallucinations in my AI agents?
The most effective way is to implement a re-ranking stage in your RAG pipeline and use Chain-of-Thought prompting. By forcing the model to cite its sources from the retrieved context and reflect on its reasoning before providing a final answer, you significantly reduce the chance of the model making things up.
Which open-source frameworks are best for starting with RAG?
LangChain, LlamaIndex, and Haystack are the industry standards for building RAG systems. They provide the necessary abstractions for connecting LLMs to vector stores and managing the data pipeline with minimal upfront cost and high flexibility.
Next Steps for Implementation
If you are starting from scratch, don't build the full agentic loop immediately. Start with a Minimum Viable Product (MVP): build a basic RAG pipeline using an open-source framework like LlamaIndex, benchmark your retrieval accuracy, and only then layer on the agentic planning capabilities.
For those already in production, your priority should be observability. Implement a logging system that captures the exact prompt and retrieved context for every failed response. This allows you to identify whether you have a retrieval problem or a generation problem, enabling you to iterate with precision rather than guesswork.
Rakesh Kumar
April 14, 2026 AT 21:01This is absolutely mind-blowing stuff! I've been struggling with my RAG setup for weeks and the part about single-topic chunking is a total game changer! It's like a lightbulb finally went off in my head!
Buddy Faith
April 15, 2026 AT 17:36lol imagine thinking these playbooks actually work’ just another way for big tech to keep us in the loop while they feed our data into a black box and pretend it's engineering’ probably just a fancy way to hide the hallucinations until the stock price peaks
Sandi Johnson
April 17, 2026 AT 11:12Oh sure, because adding a reranking stage is definitely the 'secret sauce' that will magically fix every single production error we've ever had. Pure genius. I'll just add more latency to my app and call it a feature.
Eva Monhaut
April 18, 2026 AT 15:57The distinction between a script and a library for prompt versus knowledge base is a splendid analogy. It paints such a vivid picture of how to keep a system nimble while maintaining a rich depth of information. This approach feels like a breath of fresh air for anyone drowning in prompt bloat.
Bill Castanier
April 19, 2026 AT 07:34Solid advice here. The focus on observability is key. Great breakdown.
Scott Perlman
April 19, 2026 AT 20:34this looks great’ i bet lots of people can use this to make cool things’ thanks for sharing
Tony Smith
April 21, 2026 AT 09:36It is truly heartening to witness such a comprehensive guide. I am certain that even the most novice developers will find these insights invaluable, provided they possess the fortitude to actually implement them rather than simply admiring the theory from a distance. One must wonder if we shall ever reach a point where 'engineering' is actually applied to AI, or if we shall continue to play this delightful game of trial and error indefinitely.